
Ubuntu 14.04 LTS でOCR(光学文字認識)
打ち合わせの資料など、まだ印刷物をいただくケースが多いです。
WindowsであればWordやExcelなどで資料を作っていただけるので、そのデジタルデータをいただければまったくそれで問題ないんですが、なぜか印刷してお渡しいただけるんですよね。
それでも「デジタルデータをください」といって支給していただけるのがほとんどですが、いただけないケースもあります。中には、印刷物をスキャンしたり、携帯で撮影した写真を送ってくれたり、いろいろ試行錯誤してくれちゃったりします。
まぁ・・・迷惑なケースもありますが、いろんな理由があるのでしょうね。
そこで、OCRを利用してテキストデータとして作成しようという訳です。
Ubuntu 14.04 LTS を利用して作業を行います。
環境
PCの環境は良いとして、「tesseract-ocr」と「gImageReader」と「Googleドキュメント」をそれぞれ用意します。それぞれ得手不得手があるかもしれないので、比較として作業してみます。
- Ubuntu 14.94 LTS
- tesseract-ocr
- gImageReader
- Googleドキュメント
- テキストがある画像データ
テキスト文字は以下のとおり。
テキストデータの文言は以下のとおり。
アイネクシオの売上はほどほどなので、もう少し頑張りたいです。
コンビニに寄った時、レジ横のアメリカンドックを2本衝動買いするくらいにはならないとダメですよね。
これからはもっと頑張ります。
/孝宏
画像は2点、横書きと縦書きを用意ました。


tesseract-ocr
「tesseract-ocr」はコマンドで操作します。
以下コマンドでインストール。
sudo apt-get install tesseract-ocr tesseract-ocr-jpnコマンド操作
画像データから文字を認識して、テキストに保存することができます。
$ tesseract 元となる画像名 テキスト保存ファイル名 -l jpntesseract-ocrの結果
「tesseract-orc」の横書き認識結果は以下のとおり。
ァィネク シオの売上はほどほどなので` もう少し頑張り 、 , たいです〟 コンピ二に寄つた時` レジ横のアメ リ力ン ドツクを 2本 , ` 衝動貢いする〈 らいにはならないとダメですよね。 ー これからはもつと頑張ります。 /孝宏
「tesseract-orc」の縦書き認識結果は以下のとおり。
アィネクシオの売上はほどほどなので、 もう少し頑張り たいです〝 コンピ二に寄った時、 レジ横のアメリ力ンドックを2本 衝動貢いする〈らいにはならないとダメですよね〝 これからはもっと頑張ります〝 /孝宏
画像があってもなくても、横書きでも縦書きでも、それなりに問題なさそうに見えた。
gImageReader
「gImageReader」はGUIで操作します。
「tesseract-ocr」と同じように「tesseract-ocr-jpn」を利用するようです。
以下のコマンドでインストール。
sudo add-apt-repository ppa:sandromani/gimagereader
sudo apt-get update
sudo apt-get install gimagereader tesseract-ocr-jpnGUI操作
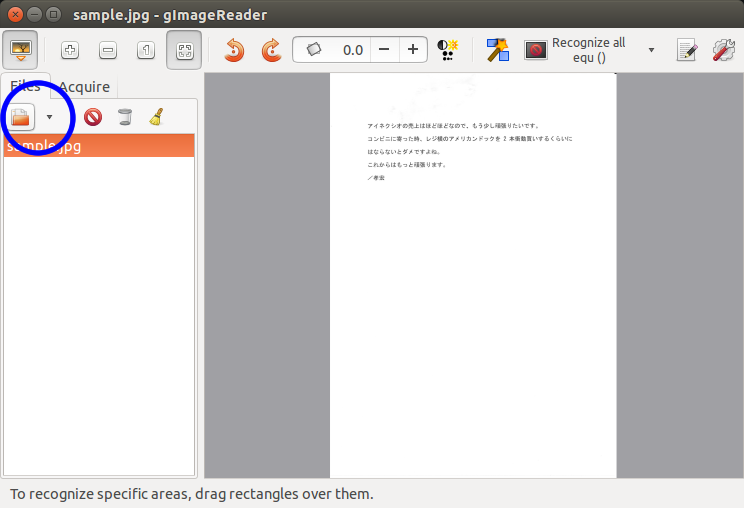
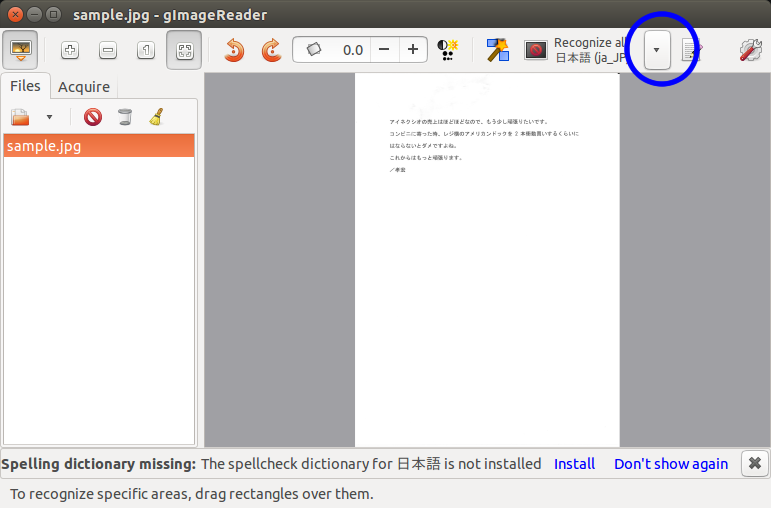
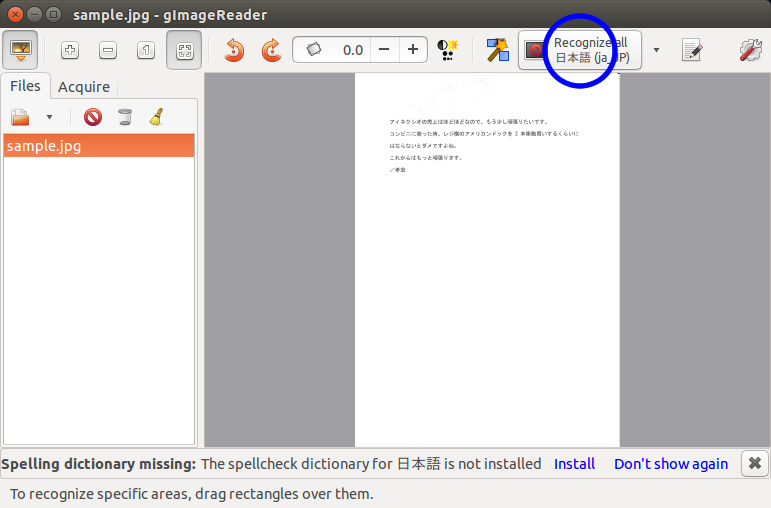
下の画像、手順1~3のような手順で操作を進めます。
手順3のあと、テキストが出力されます。
gImageReaderの結果
「gImageReader」の横書き認識結果は以下のとおり。
アィネク シオの売上はほどほどなので` もう少し頑張り 、 , たいです。 ~ ー コンピ二に寄つた時` レジ横のアメ リ力ン ドツクを 2本 , ` 衝動貢いする〈 らいにはならないとダメですよね。 ー これからはもつと頑張ります。 /孝宏
「gImageReader」の縦書き認識結果は以下のとおり。
/ こ 衝 コ た ア 孝 れ 動 2 L` ィ 宏 か 貢 ヒ で ネ ら い 二 す ク はすに〝シ もる寄 オ つ〈つ の とらた 売 頑い時 上 張に` は りはレ ほ まなジ ど す b 横 ほ 〝なの ど ぃァ な と〝メ の タリ で メ力 ` でン も すド う よツ 少 柱ク し を 頑 2 張 本 り
横書きに関してはある程度問題なさそうだけど、縦書きは暗号に見えた。
Googleドキュメント
「Googleドキュメント」はブラウザで操作します。
Googleアカウントさえあれば利用できるので、一番簡単に試せるのかな。
もうUbuntuとか関係ないけどね。
ブラウザ操作
とってもシンプル。
アップロードした画像を「右クリック」->「アプリで開く」->「Googleドキュメント」で完了。
Googleドキュメントの結果
「Googleドキュメント」の横書き認識結果は以下のとおり。
たいです。
コンビニに寄った時、レジ横のアメリカンドックを2本
アイネクシオの売上はほどほどなので、もう少し頑張り
衝動買いするくらいにはならないとダメですよね。 これからはもっと頑張ります。孝宏
「Googleドキュメント」の縦書き認識結果は以下のとおり。
アイネクシオの売上はほどほどなので、もう少し頑張り たいです。 コンビニに寄った時、レジ横のアメリカンドックを2本 衝動買いするくらいにはならないとダメですよね。 」れからはもっと頑張ります。
元のデータと一緒に出力されるのが便利。
そして内容もほぼ問題ないレベル。
まとめ
なんか圧倒的に「Googleドキュメント」が使いやすかった。
元のファイルと一緒に出力されるとか、便利でしかなかった。
用意したファイルによって結果は変わるんでしょうし、学習機能もあるようなので利用シーンによってその価値は変わるのでしょうけど、とりあえず今回は「Googleドキュメント」。
あぁ~、Ubuntuとか本当に関係なくなっちゃった。


